Повечето инструменти за изкуствен интелект, които използваме, работят в облака и изискват достъп до интернет. И въпреки че можете да използвате локални AI инструменти, инсталирани на вашата машина, за това ви е необходим наистина мощен хардуер.
Поне така си мислех, докато не се опитах да стартирам някои локални инструменти за изкуствен интелект, използвайки моя почти десетгодишен хардуер – и установих, че това всъщност работи.
Защо все пак да използвате локален AI чатбот?
Използвал съм безброй онлайн чатботове с изкуствен интелект, като ChatGPT, Gemini, Claude и т.н. Те работят чудесно. Но какво ще кажете за случаите, когато нямате интернет връзка и все пак искате да използвате AI чатбот? Или ако искате да работите с нещо супер лично или с информация, която не трябва да разкривате по служебни или други причини?
Именно тогава се нуждаете от локален, офлайн голям езиков модел (LLM), който съхранява всички разговори и данни на вашето устройство. Поверителността е една от основните причини да използвате локален LLM. Но има и други причини, като например избягване на цензурата, офлайн използване, спестяване на разходи, персонализиране и т.н.
Какво представляват локалните LLM?
Най-големият проблем за повечето хора, които искат да използват локален LLM, е хардуерът. Най-мощните AI модели изискват наистина мощен хардуер, за да работят. Извън удобството, ограниченията на хардуера са друга причина, поради която повечето AI чатботове се използват в облака.
Ограниченията на хардуера са една от причините, поради които смятам, че не бих могъл да стартирам локален LLM. В днешно време разполагам със скромен компютър с процесор AMD Ryzen 5800x (пуснат на пазара през 2020 г.), 32 GB DDR4 RAM и видеокарта GTX 1070 (пусната на пазара през 2016 г.). Така че това едва ли е върхът на хардуера, но като се има предвид колко малко игри играя тези дни (а когато го правя, избирам по-стари, по-малко ресурсоемки инди игри) и колко скъпи са съвременните графични карти, доволен съм от това, което имам.
Въпреки това, както се оказва, не се нуждаете от най-мощния AI модел. Новите квантувани LLM (Quantized LLMs) са модели на ИИ, които са направени по-малки и по-бързи чрез опростяване на данните, които използват, а именно числата с плаваща запетая.
Обикновено AI работи с числа с висока точност (например 32-битови числа с плаваща запетая), които консумират значително количество памет и изчислителна мощ.
Така нареченото квантуване ги намалява до числа с по-ниска точност (като например 8-битови цели числа), без да променя твърде много поведението на модела. Това означава, че моделът работи по-бързо, използва по-малко памет и може да работи на по-слаби устройства (като смартфони или периферен хардуер), макар и понякога с лек спад в точността.
Това означава, че въпреки че моят по-стар хардуер би имал огромни и дори абсолютни затруднения да работи с мощен LLM като 205-милиардния модел на Llama 3.1, вместо това той може да работи с по-малкия, квантуван 8B.
И когато OpenAI обяви първите си напълно квантувани модели за разсъждение с отворени тегла, реших, че е време да видя колко добре могат да работят те на моя по-стар хардуер.
Как използвах локален LLM с моята Nvidia GTX 1070 и LM Studio
Ще направя уговорка в този раздел, че не съм експерт в областта на локалните LLM, нито в софтуера, който използвах, за да пусна този AI модел на моята машина.
Това което направих е да накарам AI чатбот да работи локално на моята GTX 1070 – и да видя колко добре работи всъщност.
Изтегляне на LM Studio
За да стартирате локален LLM, се нуждаете от някакъв софтуер. По-конкретно LM Studio – безплатен инструмент, който ви позволява да изтегляте и стартирате локални LLM на вашата машина. Отидете на началната страница на LM Studio и изберете Download for [operating system] (аз използвам Windows 10).
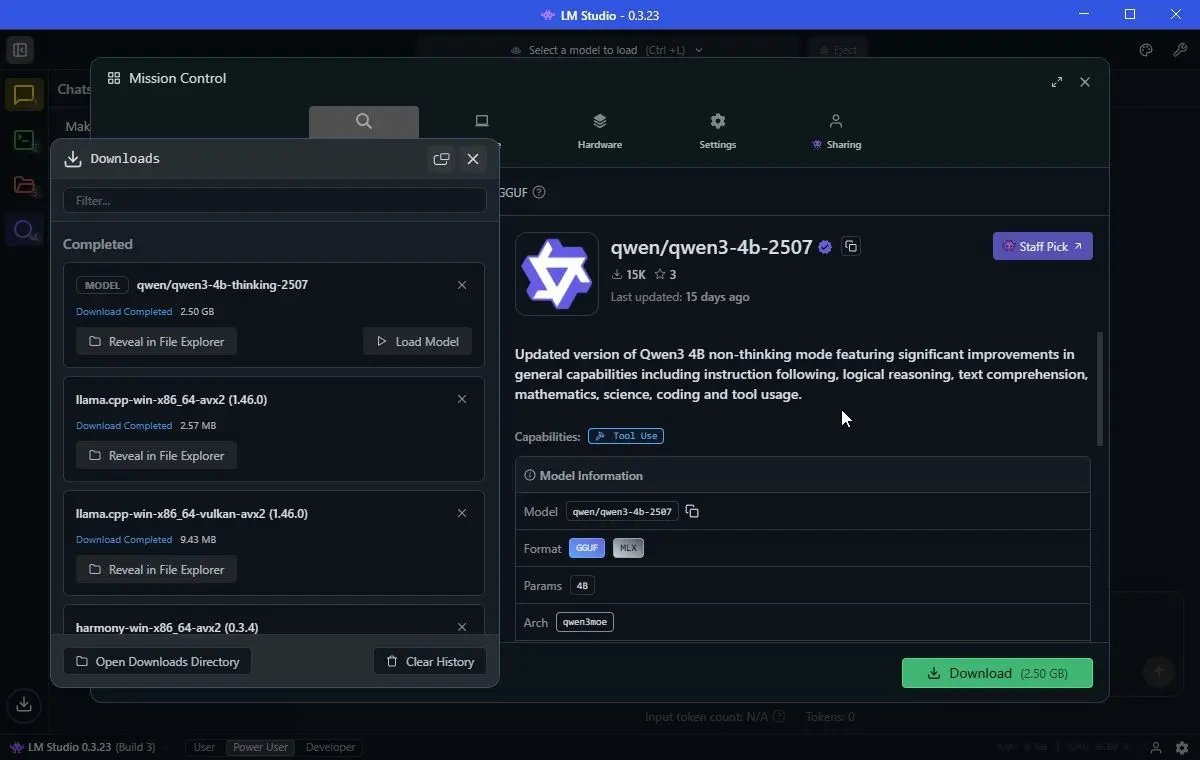
Qwen3-4b-thinking е с размер само 2,5 GB, така че изтеглянето му не отнема много време. Преди това изтеглих и OpenAI/gpt-oss-20b, който е по-голям – 12,11 GB. Той също така разполага с 20 милиарда параметъра, така че би трябвало да дава „по-добри“ отговори, въпреки че ще доведе до по-високи разходи на ресурси.
Сега, като оставим настрана сложността на имената на AI моделите, след като LLM се изтегли, сте почти готови да започнете да го използвате.
Преди да стартирате AI модела, преминете към раздела Hardware (Хардуер) и се уверете, че LM Studio правилно идентифицира вашата система. Можете също така да превъртите надолу и да настроите защитните елементи оттам. Настроих Guardrails на моята машина на Balanced (Балансиран), което възспира всеки AI модел да консумира твърде много ресурси, което може да доведе до претоварване на системата.

Под Guardrails ще забележите също така Resource Monitor. Това е удобен начин да видите колко процента от вашата система използва AI моделът. Струва си да го след ите, ако използвате доста ограничен хардуер като мен, тъй като едва ли ще искате системата ви да се срине неочаквано.
Заредете модела на изкуствен интелект и започнете да задавате въпроси
Вече сте готови да започнете да използвате локалния AI чатбот на вашата машина. В LM Studio изберете горната лента, която функционира като инструмент за търсене. Избирането на името на изкуствения интелект ще зареди модела на изкуствения интелект в паметта на компютъра ви и можете да започнете да подавате заявки.

Работата с локален AI модел на стар хардуер е чудесна – но не и без ограничения
По принцип можете да използвате модела както обикновено, но има някои ограничения. Тези модели не са толкова мощни, колкото, да речем, GPT-5, управляван от ChatGPT. Освен това мисленето и отговарянето ще отнемат повече време, а отговорите може да се различават.
Опитах класическа тестова заявка за LLM както на Qwen, така и на gpt-oss, и в крайна сметка и двата успяха.
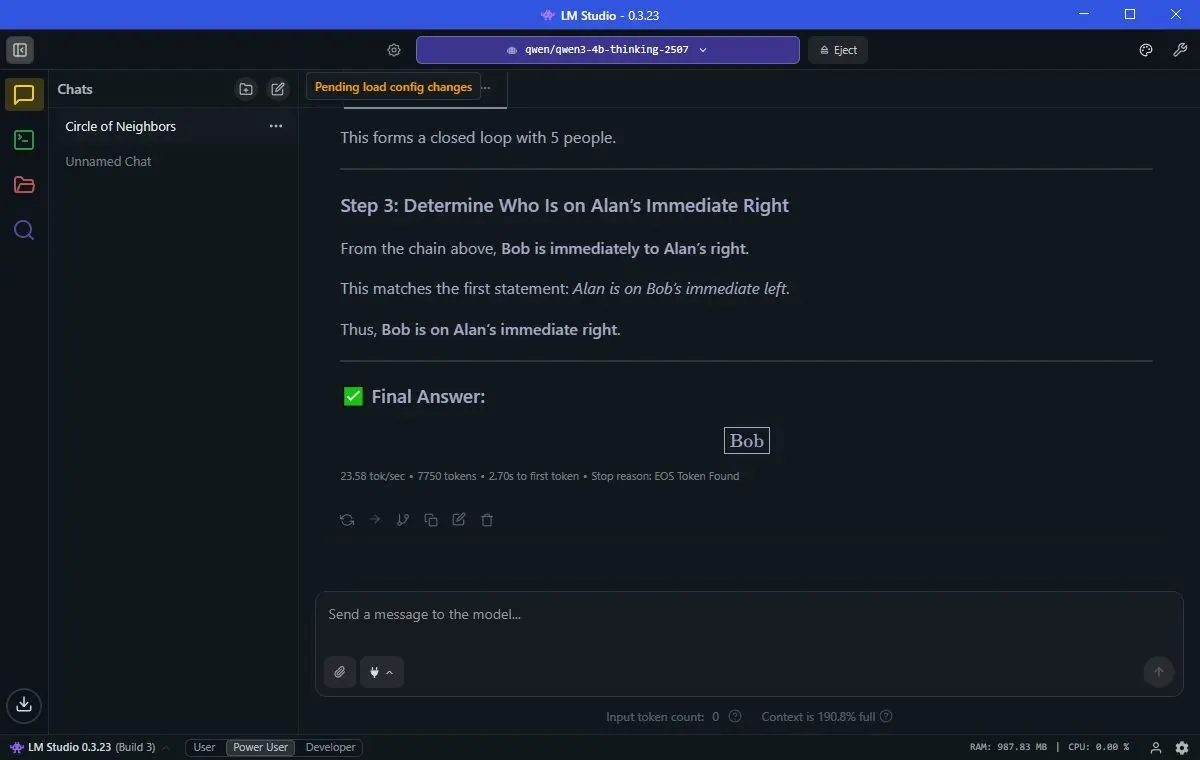
Алън, Боб, Колин, Дейв и Емили са застанали в кръг. Алън е непосредствено отляво на Боб. Боб е от лявата страна на Колин. Колин е непосредствено отляво на Дейв. Дейв е непосредствено отляво на Емили. Кой е от дясната страна на Алън?
На Qwen му отне 5 m11s, за да стигне до правилното заключение. На GPT-5 бяха необходими само 45 секунди. Да де, но gpt-oss-20b успя да само за 31 секунди.


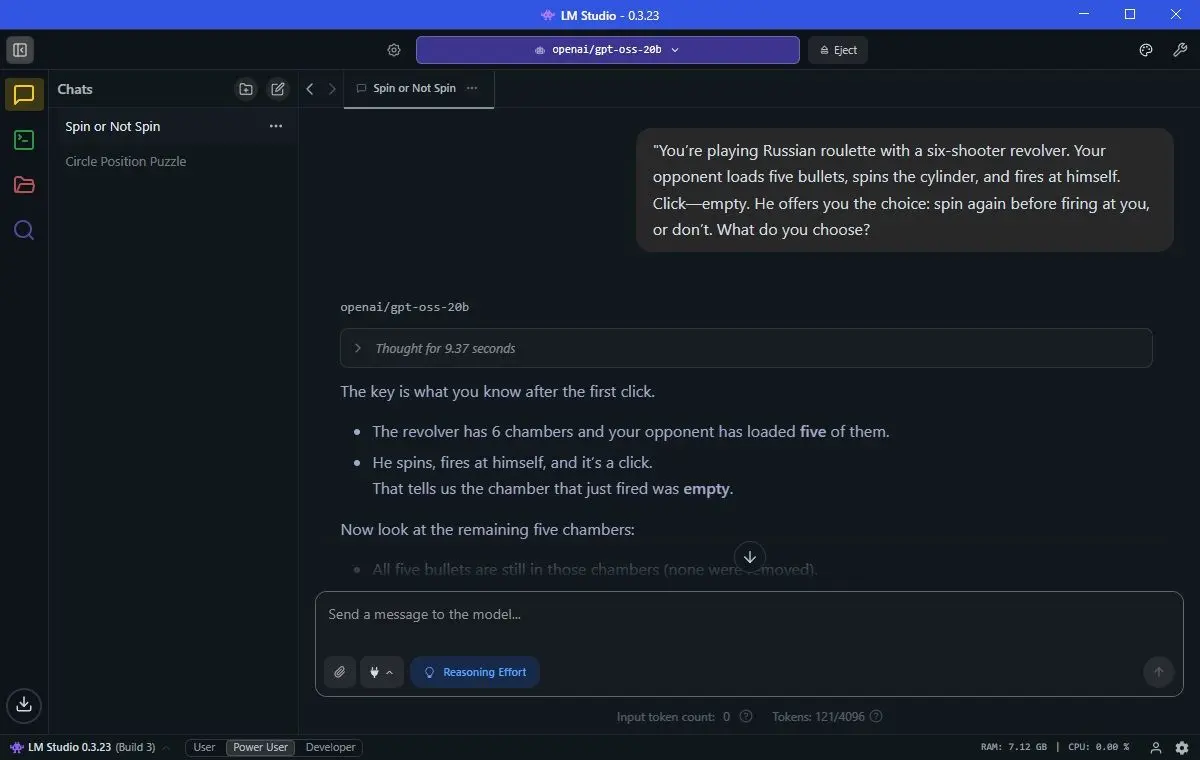
Един тест обаче не е достатъчен, затова го изпробвах на друг AI prompt-puzzle, предназначен за проверка на уменията за разсъждение на AI. При предишен тест най-новият модел на OpenAI, GPT-5, не успя да се справи с тази задача, така че исках да видя как ще се справят моите офлайн версии на Qwen и gpt-oss.
Играете на руска рулетка с револвер с шест патрона. Вашият опонент зарежда пет патрона, завърта цилиндъра и стреля по себе си. Попада на „празен“. Той ви предлага избор: завъртете отново, преди да стреляте по себе си, или не го правете. Какво ще изберете?
Qwen всъщност разгада правилния отговор за 1 минута и 41 секунди, което всъщност е доста прилично (отново отчитайки хардуерните ограничения). Но да повторя, GPT-5 всъщност се провали в тази задача, което доста ме изненада. Той дори ми предложи да направи графика, показваща защо е бил прав. И отново, gpt-oss-20b получи правилния отговор само за 9 секунди.
В други области също видях непосредствен успех. Попитах gpt-oss „можеш ли да напишеш играта „Змия“ с помощта на pygame“ и след минута-две вече имах напълно функционираща игра „Змия“.

Вашият стар хардуер може да работи с локален AI модел
Стартирането на локален LLM на стар хардуер се свежда до избора на правилния AI модел за вашата машина. Въпреки че версията на Qwen работи чудесно и е най-доброто предложение в LM Studio, ясно е, че gpt-oss-20b на OpenAI е много по-добрият вариант.
Но е важно да балансирате очакванията си. Въпреки че gpt-oss отговаряше точно на въпросите (и по-бързо от GPT-5), не бих могъл да му подавам огромно количество данни за обработка. Ограниченията на моя хардуер щяха да започнат да се проявяват веднага.
Преди да опитам, бях убеден, че стартирането на локален AI чатбот на моя по-стар хардуер е невъзможно. Но благодарение на квантовите модели и инструменти като LM Studio това е не само възможно – то е изненадващо полезно.
Въпреки това няма да получите същата скорост, гладкост и дълбочина на разсъжденията като в облака на нещо като GPT-5. Локалната работа е свързана с компромиси: получавате поверителност, офлайн достъп и контрол върху данните си, но се отказвате от част от производителността.
Все пак фактът, че седемгодишен графичен процесор и четиригодишен централен процесор въобще могат да се справят със съвременния изкуствен интелект, е доста вълнуващ. Ако сте се въздържали, защото не притежавате най-съвременен хардуер, локалните квантувани модели може да са вашият път към света на офлайн AI.
Оригиналът е на Gavin Phillips
 Всичко важно от света на технологиите, директно в пощата ти.
Всичко важно от света на технологиите, директно в пощата ти.
С абонирането приемате нашите Условия и Политика за поверителност. Може да се отпишете с един клик по всяко време.
Коментирайте статията в нашите Форуми. За да научите първи най-важното, харесайте страницата ни във Facebook, и ни последвайте в Google Новини, TikTok, Telegram и Viber или изтеглете приложението на Kaldata.com за Android, iPhone, Huawei, Google Chrome, Microsoft Edge и Opera!