Понякога се случва да четем текст в интернет и той да ти ни струва странен. На пръв поглед всичко изглежда адекватно: граматиката е правилна, няма лексикални грешки и дори пунктуацията е на място. Въпреки това нещо все още ни създава странното усещане, когато го четем – или просто виждаме странности и пропуски в текста, които обикновено не се допускат от реални хора.
С разпространението на големите езикови модели това усещане е все по-осезаемо при консумирането на различно съдържание. Читателите често предполагат, че текст, който им изглежда странен, всъщност е написан от чатботове като ChatGPT или Gemini.
На пръв поглед ситуацията тук е същата като при изображенията или видеоклиповете, генерирани от изкуствен интелект. Проблемът не е в използването на подобни инструменти при генерирането им, а във факта, че резултатът е по-странен и понякога по-лош от творенията на истински хора. Съществуват много признаци: 6 пръста, специфичен стил, размазана анимация, контекст и т.н. В такива случаи не са необходими никакви инструменти за идентифициране на AI творчеството, тъй като хората просто могат интуитивно да разпознаят фалшификата.
При текстовете обаче въпросът е по-сложен. Ако в него няма очевидни маркери, тогава е много трудно да го проследите, използвайки само собствената си интуиция. Такива явни индикатори могат да бъдат следващите фрази на изкуствения интелект: Ето проверен и редактиран вариант на вашия текст с поправки на граматически, стилистични и пунктуационни грешки“.
Въпреки това, в ситуация, в която текстът е редактиран и поне повърхностно прегледан, трябва да разгледаме по-скрити характеристики, за да разберем дали текстът е продукт на чатбот. Като първи начин за определяне на това обикновено се смятат така наречените „AI детектори“.
Какво представляват AI детекторите
Това са софтуерни системи, които откриват дали даден текст е генериран от AI. Обикновено те правят това с помощта на метрика, наречена „text perplexity“ – мярка за това колко тривиално е написан текстът.
Става дума за това, че големите езикови модели са изградени въз основа на голямо количество налично съдържание, върху което те прилагат теорията на вероятностите, за да определят най-често използваните фрази. По този начин чатботовете просто повтарят най-популярните изказвания след хората. За да се опише това, дори беше създаден терминът „стохастичен папагал“. Тази проста метафора означава, че езиковите модели по същество не разбират смисъла на казаното или езика, на който се говори, но отговарят на това, което потребителят пита, с най-вероятните отговори въз основа на ключовите думи.
Индексът „text perplexity“ в AI е много нисък, защото генерираните текстове имат най-голям брой езикови клишета, за разлика от текстовете, написани от истински хора. Чатботовете умишлено „пишат“ по много банален начин. От друга страна, хората понякога вмъкват неочевидни и сложни формулировки в изреченията си или имат специален авторски стил на писане, поради което техният индекс на „text perplexity“ е по-висок от този на чатботовете.
В допълнение към неоригиналните изказвания, вторият показател, който детекторите разглеждат са т.нар. „халюцинации“ на AI. Те се откриват много по-трудно и не всички детектори могат да го направят, тъй като са характеристика, зависеща от контекста. Халюцинациите са уверени изявления, направени от AI, които всъщност изразяват невярна, подвеждаща или фалшива информация.
Детекторите засичат халюцинации, като откриват грешно написани цитати или ги измислят, фалшиви препратки към нереални книги или просто банални несъответствия с фактите.
Основни проблеми на AI детекторите
Критериите на детекторите са ясни, но можем ли да наречем резултатите от тяхната оценка надеждни? Не, те не са точни и изчерпателни за определяне на „коректността“ на даден текст. Окончателната присъда за съдържанието винаги трябва да се прави от реален човек въз основа на собствените му наблюдения.
Легендарната история на Конституцията на САЩ е показателна в това отношение. През 2023 година потребител на Х решава да провери как детекторът ще реагира на текста на Конституцията. Оказало се, че повечето от най-авторитетните детектори смятат, че текстът на бащите основатели на САЩ е генериран от изкуствен интелект. Някои от инструментите заявили това е 96% увереност, а други – със 100%. Същото се отнася и за цитати от Библията и други класически текстове.
Някои изследователи дори смятат, че детекторите са вид измама за печелене на пари. Всъщност, въпреки факта, че голям брой детектори наистина създават такова впечатление, не всички от тях мамят потребителите. Доколко обаче те са надеждни и точни, ще стане ясно от анализа на техните цифрови показатели за ефективност.
Пример: На AI детектор се предоставя стар текст, той погрешно го разпознават като създаден от чатбот. Въпреки това са възможни и обратни ситуации. На AI детектора се дава текст, който определено е бил генериран от AI, но е цялостно редактиран или специално обработен, за да не се забележи.
От гореизложеното следва, че детекторите се справят особено зле в допускането на грешки, когато текстът е съвместно усилие на хора и AI или когато текстът е генериран по нестандартен начин.
Някой с право може да отбележи, че тази информация вече е остаряла, тъй като детекторите напредват и се развиват всяка година. Отчасти това е вярно, но отчасти фактите показват, че въпреки развитието технологията не се е подобрила много. Текущите изследвания от миналата и тази година също показват разочароваща картина.
Например, едно такова изследване сравнява добре познати детектори на академични статии: Turnitin и Originality. Според статията става известно, че мярката за „text perplexity“ има по-надеждни (но все още неточни) резултати само когато текстът е кратък, между 300 и 330 думи. В същото време и двата детектора показват поразително по-ниска ефективност при анализ на текстове между 450 и 1100 думи. По този начин този критерий също се оказа по-скоро контекстно зависим, отколкото ултимативен.
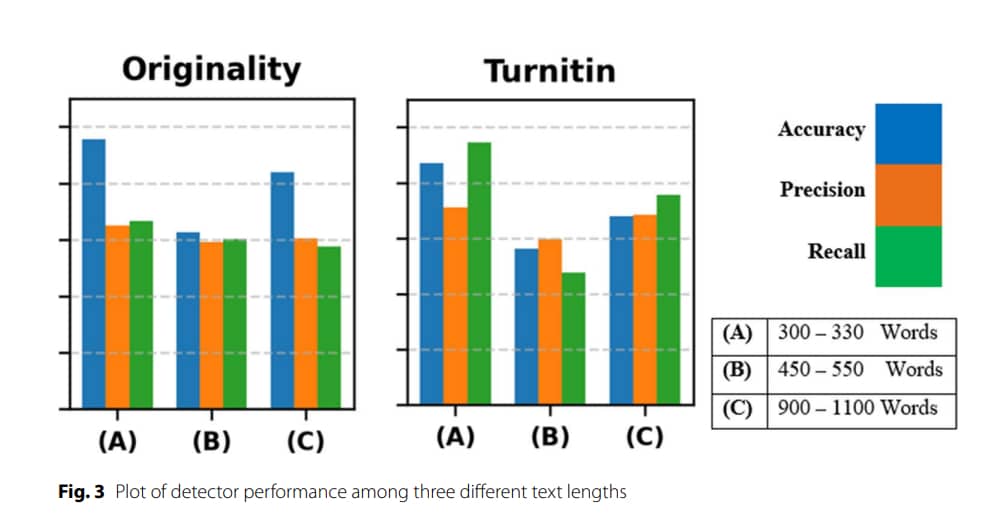
Освен това, детекторите се затрудняват по отношение на ефективността при определянето на разнообразен по жанр съдържание. Въпреки че и двата са доста добри в идентифицирането на хуманитарни текстове, написани от AI или хора, когато става въпрос за произведения в областта на науката и техниката, точността на анализа спада с почти 30%. Изследователите предполагат, че това лошо представяне се дължи на факта, че за детекторите е трудно да разграничат материалите, изпълнени със строга лексика, сложна терминология и структурирана научна конструкция.
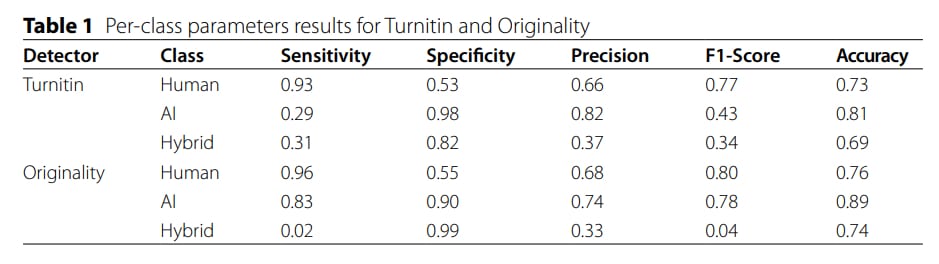
Въпреки това това не са единствените недостатъци на детекторите. В статията също така се стига до заключението, че детекторите са много слаби в идентифицирането на текстове с хибриден характер: когато се комбинират както AI, така и човешко писане. В резултат на това Originality показа „почти нулева“ способност за правилно проследяване на такива материали, а Turnitin показа много слаб резултат. По този начин, макар че детекторите са повече или по-малко калибрирани, те изпитват значителни трудности при смесени варианти.
И това са само резултатите на стандартните детектори според критерия „text perplexity“. При тези, които се опитват да търсят халюцинации, ситуацията не е по-добра. Когато става въпрос за оценка на действителните халюцинации на AI, резултатите за точност варират от 73,9% до 45,9% според различните методи и техники за анализ. Това означава, че детекторите не са в състояние ефективно да открият кога даден текст съдържа неверни факти или цитати.
Каква е алтернативата на AI детекторите?
Ясно е, че в момента детекторите не са подходящ инструмент за правилно определяне на произхода на текстовете. В обобщение, информацията от тях не трябва да се използва за правене на заключения относно качеството на материала, освен в много редки случаи и само след компетентна експертна оценка.
Какво трябва да направите, когато трябва да определите дали даден текст е написан от AI? Съществуват много хитрини за това, но нито една от тях не включва софтуерни решения. Всички те изискват човешко внимание, чувствителност и грижа. В някои от тях има и малка доза хитрост. Нищо от това няма да ви даде перфектен резултат, но ще ви даде поне малко увереност в материала, който анализирате.
Първата и най-проста стратегия е да се намерят модели на писане, подобни на тези на AI. Ерик Уонг, бивш вицепрезидент на Turnitin, заяви, че особена характеристика на текстовете на чатботовете е тяхната „изключително стабилна“ тривиалност или преднамерена безличност. Ето защо те са толкова лесни за хващане: създадени са като средно „изстискване“ от всички текстове. Ако става въпрос например за есе или статия, има шанс да се разпознае сиво съдържание от AI чрез често повтарящи се изрази, един от които споменахме в началото на статията.
Други подобни индикатори са и дългите тирета, които са традиционни за за AI и почти не се използват извън официалните документи и литературата. Чатботовете постоянно поставят тирета там, където това е неуместно.
Понякога, когато потребителите копират линкове към някои уебсайтове директно от ChatGPT, това не остава незабелязано: чатботът непременно поставя своя „знак“ върху всеки предоставен от него лник. Следователно това ще послужи и като малко доказателство за използването на чатботове при подготовката на някои текстове с линкове. Този знак изглежда в адресната лента на браузъра така: https://www.kaldata.com/about?utm_source=chatgpt.com.
Съществуват и по-контекстуални, сложни схеми. Например, в Reddit, поради наплива на чатботове, модераторите са се научили да разграничават чатботовете от потребителите по определен начин. Сред такива забележими маркери те открили повтарянето на заглавието на даден текст в съдържанието му (чатботовете обичат да правят това). Или пък разминаването между предишното съдържание на автора и сегашните му прояви: преди е писал с грешки и неструктурирано, а сега е започнал да създава перфектни текстове без визуални недостатъци.
Като цяло най-успешното и адекватно решение за идентифициране на даден текст е да се търсят халюцинации на AI. Първо, това е полезно за анализ на самото съдържание на текста, а не на неговия произход, тъй като много хора не се интересуват кой го е написал, а само от качеството му. Второ, халюцинациите понастоящем са най-ясният маркер за генериран от AI текст. Обикновеният човек не е способен да направи същите грешки, каквито правят чатботовете при разработването на материали.
Всичко това показва, че тези, които генерират текстове с помощта на изкуствен интелект, въпреки че са внимателни, все пак могат да бъдат хванати. Ето защо най-ефективният начин за определяне на продукцията на чатботовете да се търсят най-вече халюцинации. В края на краищата, ако текстът е висококачествен и добре изработен, кой се интересува от това кой го е написал? Но ако в текста например се говори за подобряване на приготвянето на пица и същевременно се предлага към рецептата да се добави лепило, тогава трябва да се замислите дали не четете текст, дело на изкуствен интелект. И за това не ви трябват никакви детектори.
 Всичко важно от света на технологиите, директно в пощата ти.
Всичко важно от света на технологиите, директно в пощата ти.
С абонирането приемате нашите Условия и Политика за поверителност. Може да се отпишете с един клик по всяко време.
Коментирайте статията в нашите Форуми. За да научите първи най-важното, харесайте страницата ни във Facebook, и ни последвайте в Google Новини, TikTok, Telegram и Viber или изтеглете приложението на Kaldata.com за Android, iPhone, Huawei, Google Chrome, Microsoft Edge и Opera!